搜索引擎做为网站流量的重要来源,网站的收录量自然是大部分网站运营人员关心的问题。
先明确一些基本点,一个网页被收录与否,有两个因素:
是否被爬虫爬过
页面质量是否过关
之前提过了收录率这么一个指标,很多网站都懒得去做这个指标,“我看看site的数据不就行了!”,事实上没有这个指标,很多工作就无从下手。从数据中找出问题,利用数据指导解决方案,分析数据验证工作成果。 最近看了《深入浅出数据分析》这个本,觉得不错,把数据分析的方法讲得很生动,建议有兴趣的从事数据分析的同学可以买本看看。任何数据分析由目标->分析->评估->决策,四个环节组成。
目标:我们想看一下网站的收录情况如何,在SEO方面是否还有提高的机会。
分析:收录情况什么算好什么算坏,是不是用一些指标来衡量?网站的收录情况是不是过于笼统,是不是应该细分下各个页面的收录情况?
评估:于是我们需要下面一些数据
・ 网站的页面层级关系
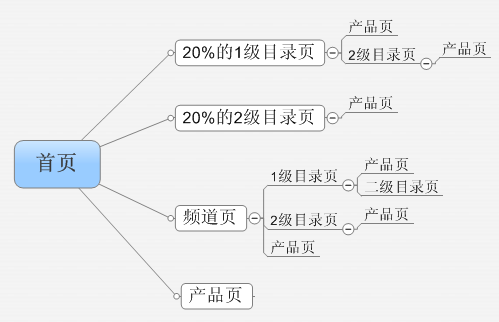
・各个层级页面带来的SEO流量
・各个层级页面的收录情况如何
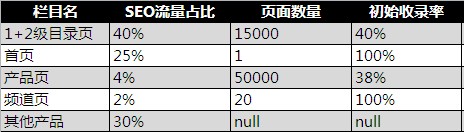
SEO流量的占比可以从Google Analytics中过滤出来。
页面数量可以从数据库获得,或者通过火车头or自制小脚本抓取统计。
收录率可以将获取的页面通过工具进行搜索,火车头也可以。
问题立马凸显!
1+2级目录页带来了大量的流量,收录率不是很好,优化收录的流量提升突破口在此!

产品页面数量很多,收录也不是很理想,但是带来的流量有限,除了收录问题,还有页面内容的问题,本文中先不管它了。
决策:我们的结论是立刻展开行动对目录页面进行收录的优化。
看到这边,似乎刚开始的目标:“通过优化收录提升流量”
演变成了新的目标:“如何提高目录页面的收录量”
这边能不能再次通过数据分析的方法进行SEO呢?
答案是肯定的!
我们再来重新走一遍 目标->分析->评估->决策 的过程
目标:提高目录页面的收录量
分析:通过本文开始的有关收录的两个因素,我们需要检查一下,网页是否被爬虫爬行过,网页的质量是不是过关。
1. 关于爬虫的情况,我们需要分析日志,才能确定。于是我们从日志中拆分一系列数据看看页面是否真的被爬行过。
2. 由于页面质量似乎是一个很难衡量的值,于是我们可以用相同模板下的:
已被爬行的页面数量/已被爬行并且被收录页面数量
来评估该模板页面质量对收录的影响大小。如果被爬的页面都被收录了,那至少说明这套页面的内容搜索引擎还算认可。(实际情况远比这个复杂,而且收录后也有可能因为质量问题被删除,但总比什么参照都没有要好,对吧!)
想认识全国各地的创业者、创业专家,快来加入“中国创业圈”
|







